C#
+ Native C による高速化〜その1:基礎知識と準備
最近は、プロセッサのクロック自体が高速になっており、通常のアプリケーションであれば、性能について特に気にする必要もなくなりつつあります。しかし、画像や音声やビデオのような大量のデータや、複雑な算術計算を実施する場合は、どうしてももっと高速に処理したいという場合が出てきます。
一方で、ハードウェアの性能向上により、4 Core, 8 Thread
などのマルチコアプロセッサがコンシューマ向けに安価に発売されており、いわゆるメニーコアの環境が整いつつあります。また、Intel
Sandy Bridge 世代以降では、Intel Advanced Vector Extensions
(AVX)が追加されました。これにより、SSEに加え、256bit命令拡張が行われ、ますますハードウェアの性能が向上しています。
このような並列化、メニーコア化の流れをうけて、.NET Framework 4.0 (Visual Studio
2010)以降では、並列処理(System.Threading.Tasks 名前空間 )が導入され、C#
でも容易に並列処理をコーディングできるようになりました。
しかしながら、現時点では C# で 100% プロセッサの性能を引き出しているかというと、そうではありません。原因の1つ目は、C#
がいったん MSIL(Microsoft Intermediate
Language)という中間言語に翻訳されますが、その中間コードを直接実行することはできず、そこからさらに機械語に翻訳されて動作します。したがって、完全にプロセッサに最適なコードが生成されているとは言えません。原因の2つ目は、また、プロセッサの浮動小数点ユニット
(FPU)に加えて、ストリーミング SIMD 拡張命令
(SSE)がサポートされおり、いわゆる並列演算がハード的に高速化されていますが、現時点で C# から SSE
を直接利用することはできません。
これらのハードウェア性能を最大限に引き出すには、どうしても Native
C、アセンブラなどの機械語レベルでの対応が必要となってきます。しかし、Native C、アセンブラを使う代償として、C#.NET
の非常に生産性の良い言語特性、.NET Framework の高機能フレームワークが使えなくなります。
C#の生産性の良さと WPF による柔軟なGUIの作成能力を維持しつつ、Native
C/アセンブラレベルでのプロセッサ性能の最大化を同時に実現するには、Managed コードから、Unmagaged
コードへの相互運用(InterOp)を呼び出すことにより、高生産性と高速処理を両立できると考えられます。
ここでは、実際に C# と Native C
による相互運用により、プロセッサの性能を最大限引き出すには、どうすればいいかについて解説します。
用語
| 用語 |
意味 |
| MMX |
Intel が1997年にPentium プロセッサ以降導入した
SIMD拡張命令セット。現在は、SSE、AVXへと進化している。 |
| SSE |
ストリーミングSIMD拡張命令 (Streaming SIMD Extensions, SSE) は、Intel
が開発したCPU のSIMD拡張命令セット、およびその拡張版の総称である。 SSE, SSE2, SSE3, SSE4,
SSE4a, Intel AVX, Intel AVX2と進化している。 |
| AVX |
MMX/SSE後継のSIMD拡張命令セットで、Advanced Vector
eXtensionsの略。Sandy Bridge
以降から搭載され、SIMD浮動小数点演算がSSEの2倍の256bitとなった。 |
| AVX2 |
Haswell 以降から搭載され、SIMD整数演算がSSEの2倍の 256bitと拡張された。 |
| SIMD |
Single Instruction Multipe Data
の略。1つの命令で、複数のデータを同時処理する並列処理手法。 |
| MIMD |
Multiple Instruction Multiple Data
の略。複数の命令で、複数のデータを同時処理する並列処理手法。 |
| Intrinsic |
ここでは、Compiler
Intrinsicsを指す。コンパイラーの組み込み命令、または組み込み関数を指し、コンパイラー固有の命令群。Visual
Studio C/C++ では、SSEなどの特殊命令を 直接記述することができる。 |
| Native |
C#, VB.NET が、MSIL
という中間言語にコンパイルされ、さらに機械語にコンパイルされて動作するのに対して、Native
C/C++では、直接機械語にコンパイルされる。 |
| MSIL |
Microsoft Intermediate Language。C#, VB.NET は、MSIL
という中間言語にいったんコンパイルされる。 |
| 呼び出し規約 |
Calling
Convention。サブルーチンを呼び出す際に、スタック、ベースポインタをどのように使用して、引数、戻り値の受け渡しを行うかの取り決め。呼び出し側、呼び出される側で、呼び出し規約が一致していないと、正しく実行できない。 |
| DLL |
Dynamil Link Library の略。複数のアプリケーションソフトから動的にリンクが可能なライブラリ。 |
| 機械語 |
CPUが直接実行可能な命令、およびデータ。 |
| アセンブラ |
アセンブリ言語のこと。機械語にほぼ一対一に対応し、人間が理解しやすいように、命令やレジスタを記述した記法。例えば、esp
レジスタの内容をebp レジスタにコピーする命令は、mov ebp,esp
と表現する。このアセンブラは、0040B7B1 という16進の機械語にアセンブルされる。 |
C#における高速化の余地
C# プログラミングにおいて、高速化可能な余地は、次の場所があります。
-
マルチコア
-
マルチスレッド
-
ネイティブコード
-
ストリーミング SIMD 拡張命令 (SSE、AVX)
しかし、Managed コードから、直接コントロールできるのは、並列処理(System.Threading.Tasks 名前空間
)からは、1.マルチコア、2.マルチスレッドだけで、3.ネイティブコード、4.ストリーミング
SIMD 拡張命令(SSE/AVX) は、Unmanaged コードからしか活用することができません。
その解決策として、並列実行可能な切り出し可能なブロックをNative コード、SSE/AVXを Unmaged
でコーディングし、それを C# Managed コードでマルチコア上に並列実行させるようにします。
Native
C プロジェクトの作成
C# と Native C
の2つのプロジェクトからなるソリューションが必要となります。このプロジェクトの作成は次のように行います。
次に、新しいプロジェクトの追加で、[他の言語]→[Visual
C++]→[Win32プロジェクト] を追加する。
Win32 アプリケーション ウィザードが表示されるので、次へ。
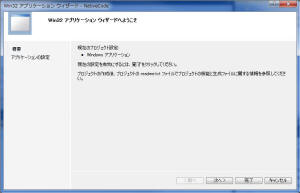
アプリケーションの設定ダイアログが表示されるので、次のように設定する。
[アプリケーションの種類] → DLL、その他のチェックボックスはオフとし、完了。
そうすると、次のようなソリューション構成となる。
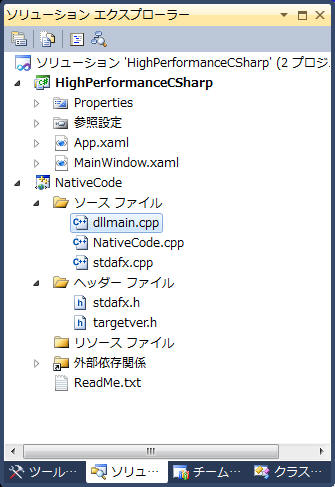
次に、実際のコーディングを始める前に、NativeCode を C#
から呼び出せるように、確認を行います。
NativeCode.cpp を編集して、次のように Add というテスト用の関数を追加します。
extern "C"
{
__declspec(dllexport) int __stdcall Add(int x, int y)
{
return x+y;
}
}
ここで、extern "C" {} とは、中括弧内をC 言語であることを指定します。これは、C#
から呼び出す際に、InterOp のDllImport を使用し、DLLからエクスポートされる C
の関数を直接 PInvoke (プラットフォーム呼び出し)を行うためです。
この extern "C" を付けずに実行すると、次の実行時例外が発生します。
EntryPointNotFoundException はハンドルされませんでした。
DLL 'DLL名' の '関数名' というエントリ ポイントが見つかりません。
ここで、 __declspec(dllexport) とは、関数を DLL から Export
するというキーワードで、必須です。
| 呼び出し規約 |
説明 |
| _cdecl |
c/c++の既定の呼び出し規約です。呼び出し元がスタックを消去します。 |
| __stdcall |
DLLの既定の呼び出し規約です。呼び出し先がスタックを消去します。これは、プラットフォーム呼び出しでアンマネージ関数を呼び出すための既定の規約です。 |
| __thiscall |
最初のパラメータは this ポインタで、レジスタ
ECX
に格納されます。その他のパラメータは、スタックにプッシュされます。この呼び出し規約は、アンマネージ
DLL からエクスポートしたクラスのメソッドを呼び出すために使用します。 |
| __fastcall |
この呼び出し規約はサポートされていません。 |
この __declspec(dllexport) や、__stdcall を指定せずに C#
より呼び出すと、PInvoke 時のシグネチャが一致せず、次の実行時例外が発生します。
PInvokeStackImbalance が検出されました。
PInvoke 関数がスタックを不安定にしています。PInvoke シグネチャがアンマネージ ターゲット
シグネチャに一致していないことが原因として考えられます。呼び出し規約、および PInvoke
シグネチャのパラメーターがターゲットのアンマネージ シグネチャに一致していることを確認してください。
次に、NativeCode
をコンパイルします。この場合だと、\HPCSharp\HighPerformanceCSharp\Debug
または Release の下に、NativeCode.dll が作成されていることを確認します。
次に、作成した NativeCode.dll から、関数が正しく Export
されている確認するには、Visual Studio コマンド プロンプト (2010)
を起動し、次のコマンドを実行します。
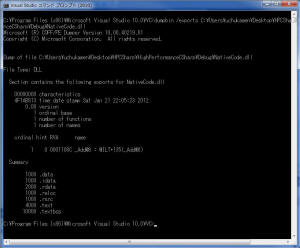
dumpdll.exe
/exports \HPCSharp\HighPerformanceCSharp\Debug\NativeCode.dll
次にように、Add 関数が Export されていることを確認します。
メインの
C# プロジェクトを追加する
Visual Studio で C# WPF などで、メインプロジェクトを作成します。
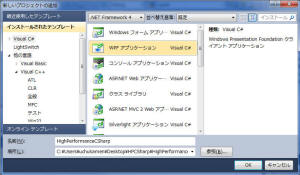
ここでは、WPF アプリケーションを使用します。
この時、C# から、NativeCode.dll
を呼び出す必要がありますが、NativeCode.dll
は、\HPCSharp\HighPerformanceCSharp\Debug または Release
の下に、NativeCode.dll が作成されています。
一方、C# プロジェクトでの実行ファイル、この場合は
\HPCSharp\HighPerformanceCSharp\HighPerformanceCSharp\bin\Debug
または Release の下に、HighPerformanceCSharp.exe が作成されています。
Windows では、 DLL を呼び出す場合に次の順番で DLL を検索します。
-
実行中のプロセスの実行形式モジュールがあるフォルダ。
-
現在のフォルダ。
-
Windows システム フォルダ。
-
Windows ディレクトリ。
-
環境変数 PATH 内に記述されたフォルダ。
ここでは、実行中のプロセスの実行形式モジュールがあるフォルダと同じ場所に DLL
を配置することにします。対応としては、C# のメインモジュールが出力する場所を、DLL
と同じ\HPCSharp\HighPerformanceCSharp\Debug または Release の下にします。
具体的には、C# の HighPerformanceCSharp の
プロジェクトのプロパティから[ビルド]タブ→[出力]→[出力パス]を変更します。
この時、[ビルド]タブ→[構成] で、Debug と Release
でそれぞれ出力場所が違うので、Debug のときは Debug、Release のときは Release
パスにしないと、正しくリンクされないので注意してください。
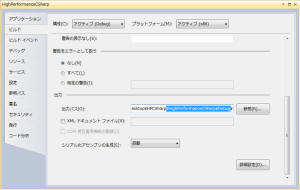
次に、ソリューションのプロパティを開きます。
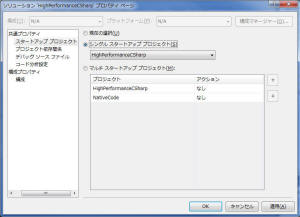
ここで、[共通プロパティ]→[スタートアップ プロジェクト]→シングル スタートアップ
プロジェクトを HighPerformanceCSharp にセットします。
次に、[共通プロパティ]→[プロジェクト依存関係]で、HighPerformanceCSharp
の依存先に NativeCode を指定します。
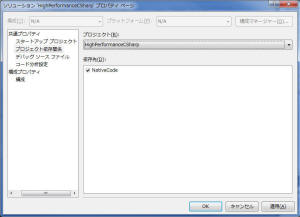
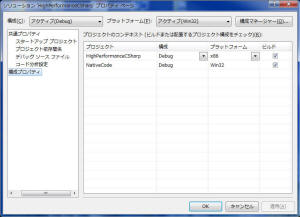
これにより、正しく依存関係がセットされ、正しくコンパイル実行ができるようになります。
もしファイルを変更したのにビルドがうまくかからない場合は、ソリューションの構成プロパティで、両方のファイルにビルドがチェックされているか確認してみてください。
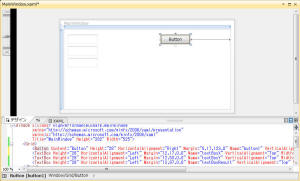
では、DLL を C# から呼び出してみます。WPF
のメイン画面で次に様な加算を実行するために、ボタンとテキストボックスを配置して、ボタンをダブルクリックして、次のようにボタンのイベントハンドラを追加します。
...
using System.Runtime.InteropServices;
using System.Diagnostics;
中略
[DllImport("NativeCode.dll")]
static extern int Add(int x, int y);
private void button1_Click(object sender, RoutedEventArgs e)
{
var x = Int32.Parse(textBoxX.Text);
var y = Int32.Parse(textBoxY.Text);
textBoxX.Text = Add(x, y).ToString();
}
実行して、ボタンを押すと、123 + 234 の結果である 357
が表示されていると思います。(エラー処理は省略してあります。)
コンパイラによるネイティブコードの最適化
さて、以上でネイティブコードの実行環境が整いました。次にコンパイラによるネイティブコードの最適化を見ていきます。
NativeCode
プロジェクトのプロパティを開き、コンパイル時の設定を確認します。このとき、左上の構成が、Debug と
Release でそれぞれ異なる構成を設定できるようになっているので、注意してください。
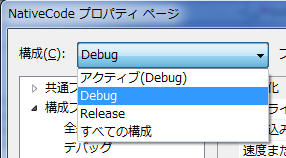
まず、Debug ですが、[構成]→[構成プロパティ]→[C/C++]→[最適化]
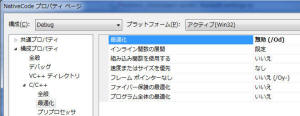
では、次のように最適化が無効になっています。また、またその他の最適化はオフになっています。これは最適化によるコードが最適化されることによりデバッグに支障ができないようにしているためです。Debug
構成時には、これらの最適化のスイッチは必要のない限り変更することはありません。
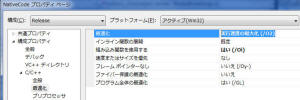
次に、Release
時の設定を確認します。デフォルトで、最適化が実行速度の最大化(/O2)、組み込み関数を使用するがはい(/Oi)となっています。
次に、[構成]→[構成プロパティ]→[C/C++]→[コード生成]を確認します。
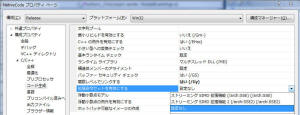
デフォルトでは、拡張命令セットを有効にするが、設定なしになっています。これを /arch:SSE2
にセットすると、コンパイラが自動的にSSE2命令セットを使用して最適化してくれます。
コンパイラオプションの設定は非常に多く、詳細については次のURLを参照してください。
http://msdn.microsoft.com/ja-jp/library/19z1t1wy(v=vs.100).aspx
インラインアセンブラ
32bit 環境の C++
では、インラインアセンブラがサポートされています。しかしながら、アセンブラを使う必要はないと思います。
理由は、C++
Nativeコンパイラーの最適化により、下手にアセンブラで組むより、確実で高速なコードを生成してくれます。つぎに、どうしても必要であれば、Compiler
Intrinsics
がサポートされおり、下手なアセンブラより高速な演算でプロセッサ固有の命令を実行することができます。また、CPUID命令、SSE命令などプロセッサの性能を最大限利用するための命令群も豊富にサポートしています。さらに、x64
ビット環境では、インラインアセンブラはサポートされていません。以上より、アセンブラを使う必要はないと思います。むしろ、使うべきではないと思います。
とはいえ、どのようにインラインアセンブラを利用できるのか、簡単に説明します。
次のテストコードを NativeCode.cpp に追加してください。
__declspec(dllexport) int __stdcall AsmAdd(int
x, int y)
{
__asm
{
mov eax, x
add eax, y
}
}
ここでは、プロセッサの eax レジスタに、x を代入し、eax に y を加算します。eax
の値は、そのまま関数の戻り値となります。
この AsmAdd を呼び出し側は
[DllImport("NativeCode.dll")]
static extern int AsmAdd(int x, int y);
private void button2_Click(object sender,
RoutedEventArgs e)
{
var x = Int32.Parse(textBoxX.Text);
var y = Int32.Parse(textBoxY.Text);
textBoxResult.Text = AsmAdd(x, y).ToString();
}
実際にアセンブラがどのように生成されているのか確認してみます。NativeCode
プロジェクトのプロパティで、[構成プロパティ]→[C/C++]→[出力ファイル]で、[アセンブリの出力]で、アセンブリコードとソースコード(/FAs)
を指定します。これで、アセンブラファイルが出力されます。
C++ の Add 関数が次のように mov と add 命令で構成されています。
_TEXT SEGMENT
_x$ = 8 ; size = 4
_y$ = 12 ; size = 4
_Add@8 PROC ; COMDAT
; 9 : {
push ebp
mov ebp, esp
sub esp, 192 ; 000000c0H
push ebx
push esi
push edi
lea edi, DWORD PTR [ebp-192]
mov ecx, 48 ; 00000030H
mov eax, -858993460 ; ccccccccH
rep stosd
; 10 : return x+y;
mov eax, DWORD PTR _x$[ebp]
add eax, DWORD PTR _y$[ebp]
; 11 : }
pop edi
pop esi
pop ebx
mov esp, ebp
pop ebp
ret 8
_Add@8 ENDP
_TEXT ENDS
一方、インラインアセンブラでコーディングした部分は、次のように同等のコードが生成されていることがわかります。
; COMDAT _AsmAdd@8
_TEXT SEGMENT
_x$ = 8 ; size = 4
_y$ = 12 ; size = 4
_AsmAdd@8 PROC ; COMDAT
; 14 : {
push ebp
mov ebp, esp
sub esp, 192 ; 000000c0H
push ebx
push esi
push edi
lea edi, DWORD PTR [ebp-192]
mov ecx, 48 ; 00000030H
mov eax, -858993460 ; ccccccccH
rep stosd
; 15 : __asm
; 16 : {
; 17 : mov eax, x
mov eax, DWORD PTR _x$[ebp]
; 18 : add eax, y
add eax, DWORD PTR _y$[ebp]
; 19 : }
; 20 : }
pop edi
pop esi
pop ebx
add esp, 192 ; 000000c0H
cmp ebp, esp
call __RTC_CheckEsp
mov esp, ebp
pop ebp
ret 8
_AsmAdd@8 ENDP
_TEXT ENDS
次の例は、CPUID の情報をインラインアセンブラで取得する例です。
渡された char* に書き込む場合の Native C 側
void TestClass::GetVenderSignature(char*
vender_sig)
{
__asm
{
mov eax, 0; ; /* Vender Signature を取得するindex */
cpuid; ; /* CPUID を実行*/
mov eax, vender_sig
mov dword ptr [eax], ebx; ; /* 最初の4文字*/
mov dword ptr [eax + 4], edx; ; /* 次の4文字*/
mov dword ptr [eax + 8], ecx; ; /* 最後の4文字*/
mov byte ptr [eax + 12], 0; ; /* */
}
return;
}
C# 呼び出し側
[DllImport("NativeCode.dll")]
static extern void AsmCpuid(IntPtr buff);
IntPtr unmanagedBuf =
Marshal.AllocHGlobal(32);
AsmCpuid(unmanagedBuf);
string ansiStr =
Marshal.PtrToStringAnsi(unmanagedBuf);
textBoxResult.Text = ansiStr;
Marshal.FreeHGlobal(unmanagedBuf);
Compiler
Intrinsics
Inrinsics とは、固有のという意味があり、Visual Studio では、Compiler
Intrinsics で、x64, Itanium, MMX, SSE, SS2
などの強力なサポートがあります。Intrinsics
の特徴として、バッファのアライメントを考慮したり、最適なコードに展開してくれたり、あるいは他のアーキテクチャと共通であったり、しばしばアセンブラより高速な処理が可能です。このため、アセンブラを使うぐらいなら、この
Intrinsics の活用を考えてみたほうがよいでしょう。ただし、この
Intrinsicsは、Native C/C++ からしか使用できません。
次の例は、CPUID の情報を Intrinsics で取得する例です。
#include <intrin.h>
__declspec(dllexport) void __stdcall
IntrinsicCpuid(char* CPUString)
{
int CPUInfo[4];
__cpuid(CPUInfo, 0);
*((int*)CPUString) = CPUInfo[1];
*((int*)(CPUString+4)) = CPUInfo[3];
*((int*)(CPUString+8)) = CPUInfo[2];
*((int*)(CPUString+12)) = 0;
}
C# 呼び出し側
[DllImport("NativeCode.dll")]
static extern void IntrinsicCpuid(IntPtr buff);
IntPtr unmanagedBuf = Marshal.AllocHGlobal(32);
IntrinsicCpuid(unmanagedBuf);
string ansiStr =
Marshal.PtrToStringAnsi(unmanagedBuf);
textBoxResult.Text = ansiStr;
Marshal.FreeHGlobal(unmanagedBuf);
同様に、SSE 命令を intrinsic でコーディングした例です。
#include <stdio.h>
#include <tmmintrin.h>
int main ()
{
__m128i a, b;
a.m128i_i16[0] = 1;
a.m128i_i16[1] = 1;
a.m128i_i16[2] = 100;
a.m128i_i16[3] = -100;
a.m128i_i16[4] = -1000;
a.m128i_i16[5] = 1000;
a.m128i_i16[6] = 100;
a.m128i_i16[7] = 52;
b.m128i_i16[0] = -128;
b.m128i_i16[1] = -64;
b.m128i_i16[2] = 32;
b.m128i_i16[3] = 4096;
b.m128i_i16[4] = 2;
b.m128i_i16[5] = -2;
b.m128i_i16[6] = 32000;
b.m128i_i16[7] = 0;
__m128i res = _mm_add_epi32(a,
b);
printf_s("Original
a:\t%6d\t%6d\t%6d\t%6d\n\t\t%6d\t%6d\t%6d\t%6d\n",
a.m128i_i16[0], a.m128i_i16[1], a.m128i_i16[2],
a.m128i_i16[3],
a.m128i_i16[4], a.m128i_i16[5], a.m128i_i16[6],
a.m128i_i16[7]);
printf_s("Original
b:\t%6d\t%6d\t%6d\t%6d\n\t\t%6d\t%6d\t%6d\t%6d\n",
b.m128i_i16[0], b.m128i_i16[1], b.m128i_i16[2],
b.m128i_i16[3],
b.m128i_i16[4], b.m128i_i16[5], b.m128i_i16[6],
b.m128i_i16[7]);
printf_s("Result
res:\t%6d\t%6d\t%6d\t%6d\n\t\t%6d\t%6d\t%6d\t%6d\n",
res.m128i_i16[0], res.m128i_i16[1], res.m128i_i16[2],
res.m128i_i16[3],
res.m128i_i16[4], res.m128i_i16[5], res.m128i_i16[6],
res.m128i_i16[7]);
return 0;
}
以上のように、アセンブラを使う必要もなく、プロセッサ固有の命令を記述することができます。
ただし、アセンブラと同様、Intrinsics
は非常に多くの命令がある一方、それに関する情報は少なく、どのようなことができるのか把握するのに非常に苦労します。そのようなときには、Intel
から ガイドが提供されています。
http://software.intel.com/en-us/avx/
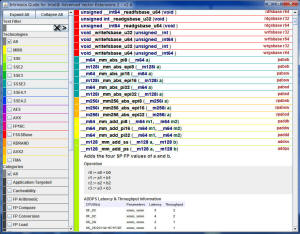
ここから、Intel Intrinsic Guide(Windows)
をダウンロードできます。このツールでは、Intrinsic を
MMXからAVXまでカバーしていて、テクノロジー別、カテゴリー別にある程度絞り込みができるので、Intrinsic
を手書きする場合は、便利です。
ただし、Native C/C++ では、コンパイラーが SSE/SSE2
命令を使った最適化を行ってくれるため、 へたに Intrinsic を使うよりは、まずはコンパイラーの最適化を活用し、コードをなるべく
C/C++ でとどめておくほうが良いでしょう。
その他のアプローチ
Native Code を呼び出す方法には、C# から Native C
を呼び出す以外に、C++だと、同様の PInvoke 、C++
InterOp(暗黙のPInvoke)、C++ COM InterOpなどが考えられます。
C++ からの InterOp をするぐらいなら、あえて C# を使う必要はなく、C++/CLI から
C++ InterOp(暗黙のPInvoke)呼び出しをしたほうが良いと思います。
C++ InterOp(暗黙のPInvoke)に関しては、次を参考にしてください。
http://msdn.microsoft.com/ja-jp/library/2x8kf7zx.aspx
COM の場合、手順が複雑になるのと、regsvr32 により COM
をインストールすることにより、かえって管理が面倒になり、個人的には好きではありません。すでに COM
がある場合は、こちらを参考にするとよいでしょう。
http://msdn.microsoft.com/ja-jp/library/cc439986(v=vs.71).aspx
7.まとめ
以上で、C# から Native C呼び出しによる高速化の準備ができました。
次回は、画像処理を例に、C# + Native C でどこまで高速化できるか、実験したいと思います。