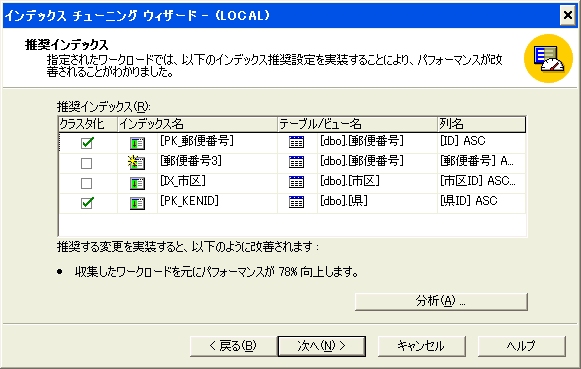
また、その設定でインデックスを作ってくれたり、次のようにスクリプトも自動作成してくれる。
/* Created by: Index Tuning Wizard */
/* 日付: 2005/09/18 */
/* 時刻: 8:41:18 */
/* サーバー名: (LOCAL) */
/* データベース名: ZipCode */
/* ワークロード ファイル名: ...\Zip.sql */
USE [ZipCode]
go
SET QUOTED_IDENTIFIER ON
SET ARITHABORT ON
SET CONCAT_NULL_YIELDS_NULL ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
SET NUMERIC_ROUNDABORT OFF
go
DECLARE @bErrors as bit
BEGIN TRANSACTION
SET @bErrors = 0
CREATE NONCLUSTERED INDEX [郵便番号3] ON
[dbo].[郵便番号] ([郵便番号] ASC, [県ID] ASC, [市区ID] ASC, [町名] ASC )
IF( @@error <> 0 ) SET @bErrors = 1
IF( @bErrors = 0 )
COMMIT TRANSACTION
ELSE
ROLLBACK TRANSACTION